
이것만으로는 약간 헷갈려서 구글링해서 좀 더 찾아보았다.
Building an Image Recognition Model for Mobile using Depthwise Convolutions
Deep Learning algorithms are excellent at solving very complex problems, including Image Recognition, Object Detection, Language…
heartbeat.fritz.ai
이 링크 보고 이해함
C: 채널 수
N: 필터(커널) 개수
K: 필터(커널) 가로세로 사이즈
W,H : 인풋의 가로세로
라고 한다면
SATNDARD CONVOLUTION
우리가 기본적으로 아는 컨볼루션이다.
C만큼의 채널 수(보통은 RGB 3개)를 가진 K^2 사이즈 필터가 N개 있으므로
파라미터 개수는 C * (K^2 * N)이 된다
아웃풋은 W*H*N
DEPTHWISE SEPARABLE CONVOLUTION
정확히는 Depth-wise + Point-wise 두단계로 나누어진 컨볼루션을 의미
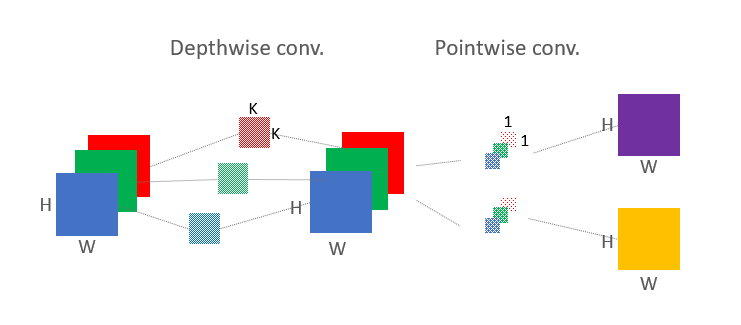
Depathwise convolution에서 C 갯수만큼의(보통 RGB 3장) 사이즈 K^2 필터가 있고 각각의 채널에 각각 컨볼루션 적용
기존의 convolution처럼 각 채널들을 더해주는 과정이 없다.
파라미터 개수는 C * K^2
이때 아웃풋은 W*H*C (padding하면 인풋사이즈와 똑같다)
Pointwise convolution는 Standard Convolution과 같다. 하지만! 필터 사이즈 K가 1이라서 특별히 이름붙여졌다.
C만큼의 채널수를 갖는 N개의 필터가 있으며 K는 1
따라서 파라미터 개수는 C*N*K^2 = C*N
아웃풋은 W*H*N
기존 컨볼루션과 아웃풋 사이즈는 같다
각 컨볼루션을 다른 레이어라고 보면 총 파라미터 개수는 그냥 다 더하면된다
C*K^2 + C*N = C * (K^2+N)
기존 convolution과 비교했을 때 곱연산이 덧셈으로 바뀌었으므로 웬만하면 기존보다 적은 파라미터수를 갖는다
이렇게 기존보다 적은 파라미터로 비슷한 연산을 할 수 있다
'Study > 머신러닝' 카테고리의 다른 글
| Tensorflow CuDNN RNN vs 그냥 RNN 비교 (0) | 2020.05.12 |
|---|---|
| Bazel을 이용해 Tensorflow Lite 빌드해보기 (1) | 2020.03.31 |
| Tensorflow2.0 / CUDA / Nvidia driver 호환 (0) | 2020.02.14 |
| docker 에서 한국어 설정하기 (0) | 2020.02.05 |
| Keras에서 binary_crossentropy와 categorical_crossentropy 차이 (0) | 2019.12.16 |

댓글